 一直比较关心百度收录网站的情况,因为国内用户多数使用百度搜索。但是对于 WordPress 平台的站点,百度的收录以及对收录页面的辨识和处理似乎不怎么好。所以我干脆使用 robots 来限制百度对网站的访问。一个多月过去了,似乎效果已经稳定了,特此记录。
一直比较关心百度收录网站的情况,因为国内用户多数使用百度搜索。但是对于 WordPress 平台的站点,百度的收录以及对收录页面的辨识和处理似乎不怎么好。所以我干脆使用 robots 来限制百度对网站的访问。一个多月过去了,似乎效果已经稳定了,特此记录。
当然,需要提前声明的是,我搜索引擎优化(SEO)没有很深的研究,以下内容纯粹是针对水景一页网站一段时间内的表现的一个记录和个人的一点儿粗浅认识和分析。仅供参考!若因此而造成您损失,请恕作者要不负责任了。(嗯,这一段是给某些人看的 :D)
1. 我的 robots 配置¶
对于单站点的 WordPress 和多站点模式(Multisite)的 WordPress,其链接结构有所不同,这个需要特别注意。像这种禁止爬虫访问的配置,如果不小心把需要收录的页面地址给包含进去了,那就得不偿失了。
水景一页这个主站采用的是多站点模式。我大概是在 2012年9月底的时候在 robots.txt 文件中增加了下面的配置:
# Baidu only,多站点模式 User-agent: Baiduspider # 禁止访问回复评论页面 Disallow: /*?replytocom=* # 禁止访问分页页面 Disallow: /page/ Disallow: /*/page/ # 禁止访问分类、标签、作者页面 Disallow: /*/category/ Disallow: /*/tag/ Disallow: /*/author/ # 禁止访问存档页面,包括年份存档和月份存档 Disallow: /blog/2009/ Disallow: /blog/2010/ Disallow: /blog/2011/ Disallow: /blog/2012/ Disallow: /blog/2013/
对于另一个非多站点模式的 WordPress 安装,则使用了下面的规则:
# Baidu only,非多站点模式 User-agent: Baiduspider # 禁止访问回复评论页面 Disallow: /*?replytocom=* # 禁止访问分页页面 Disallow: /page/ Disallow: /*/page/ # 禁止访问分类、标签、作者页面 Disallow: /category/ Disallow: /tag/ Disallow: /author/ # 禁止访问存档页面,包括年份存档和月份存档 # 之所以注释掉下面的规则,是因为链接形式为 /2012/12/post-name/ # 下面的规则会将需要收录的文章页面也给禁止了 #Disallow: /2011/ #Disallow: /2012/ #Disallow: /2013/
注:# 号后面的内容是注释
2. 为什么要这么做?——我的分析¶
这么做当然会减少百度对网站的收录数量,但是我认为光有数量没有质量也是不行的。
对于 ?replytocom=
这是在文章或者静态页面上对某人的评论进行回复时,点击回复按钮后页面地址所呈现的形式。当有较多评论时,该页面就会很多带有不同数字的这种类型的链接地址,也就是说,不同的地址,同一个页面。
这个问题在 WordPress 的开发论坛也有过较多讨论,最后采取的做法是,当地址中含有该参数时,会在页面的 Header 中加入 nofollow, noindex 声明。但是我最近的测试发现百度似乎对这个规则处理的不好。详见百度没有严格遵守 noindex nofollow 规则。
这样一来,即使百度没有因为多地址对应单页面而惩罚网站,也会因为对同一内容的搜索点击数被分散而影响该页内容在搜索结果中的排名。
对于归档页
另外一类就是归档页面,如分类(category)页、标签(tag)页、作者(author)页,还有分页(paged)。当然,还包括按照日期进行存档的归档页。这些页面实际就是具有某一类共同属性的文章的列表,并不是什么新东西。而用户搜索,希望看到的多数时候是文章或者静态页面的内容,而不是这些归档页面。
据我观察,百度在这方面至少存在以下问题:
- 归档页更新不及时。当用户点击归档页面/分页后,可能内容所对应的文章已经进入到下一分页了,这自然导致用户没有找到想要的东西,至少是不够直接。
- 在搜索结果中针对该条目所显示的摘要不够准确。通常,文章页可以使用我们自己编写的摘要文字(description),可是分类等归档页面却没有。而百度在自动生成这种描述性摘要的时候,本领实在不咋的,经常会看到它将发表日期、浏览数等文字给弄进了这种搜索结果描述里。那么,用户看到这种搜索结果,点击浏览的兴趣就大降。
- 挤占相关性更强的文章或者静态页面在搜索结果中的展示机会。当用户搜索某一内容的时候,搜索引擎可能直接给他文章页的结果,也可能给他这种归档页的结果。如果搜索结果与搜索词的相关性处理得好,这倒更好;可如果明明文章页更相关,搜索引擎却给了某个归档页,那就不合适了。
基于上面的分析,我最终决定通过 robots.txt 设置规则完全禁止百度收录那些内容,帮助它提高展示更相关内容的能力。实际上同为搜索引擎的 Google,也会收录上述禁止 Baiduspider 访问的页面,可是根据我长期观察的经验,Google 更倾向于向搜索者展示文章的页面。
3. 这段时间百度收录的数据¶
进行搜索引擎优化的目的无非就是希望提高通过搜索引擎过来网站的访问量。一方面靠网站内容在搜索结果中有个好的排名,一方面靠提高网站内容在搜索结果中的展示次数。但是最终搜索引擎带来的访问量是由(展示次数*点击率)决定的。
采取上述措施后至少会对提高点击率有帮助,也许会降低展示次数。至于综合来看会有什么样的结果还真是不好说。并且,下面提供的这段时间百度对水景一页的收录情况和通过百度搜索引入的访问量都是很片面的,并不能作为上述分析结果正确的明证。请读者朋友慎思。
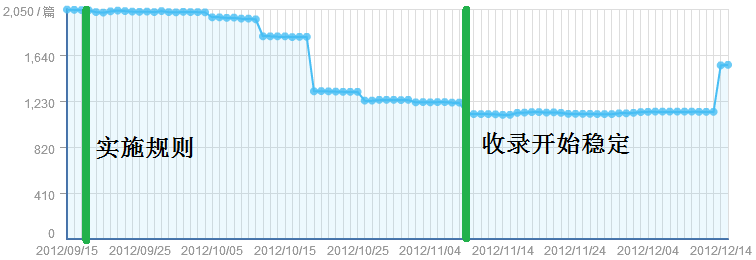
实施禁止Baiduspider访问部分内容的规则前后百度索引量的变化
上图是实施禁止Baiduspider访问部分内容的规则前后百度索引量的变化情况。其中于 2012年12月14日突然增加了 416 条收录,不知道是什么引起的,也不知道是收录的什么内容。应该跟实施上述访问规则无关。
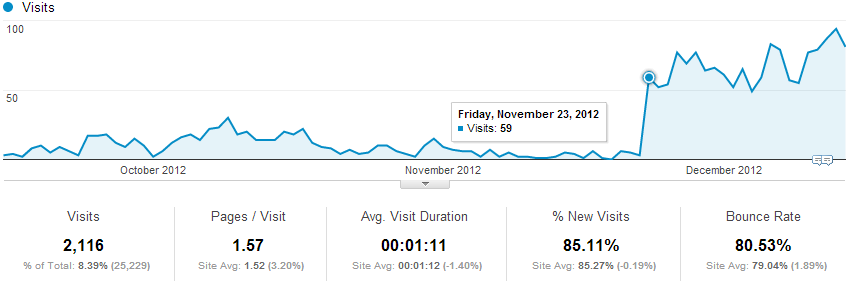
此段时间中 Google 统计中来自百度的访问量,变化明显的点日期为2012.11.23
在实施上述规则后,来自百度搜索的访问量变化情况。可惜的是,小站在百度的情况很差,访问量很少,看不出什么情况。图中变化明显的点是 2012年11月23日,并不知道它与访问规则调整有多大关系。
度娘的脾性比较不好把握,而且因为某些原因,度娘对小站可是打击了很多次。可能以后都不会再针对百度做更多地优化和观察,所以就把这段时间观察的结果记录下来,尽管这些结果也许没什么参考价值。©
本文发表于水景一页。永久链接:<https://cnzhx.net/blog/restrict-baidu-index-with-robots_txt/>。转载请保留此信息及相应链接。
引用通告: 屏蔽一些不友好的蜘蛛 | 水景一页
引用通告: 百度联盟分账权限被关闭 | 水景一页
Baidu spider 是无视 robots.txt 的….
嗯,不过,虽然它基本到处乱爬,但是这么设置了之后,百度已经不收录我的 replytocomm 链接了,所以还是有效果的。
不管了…
累了?
阅。
汗,你这是做个标记吗?